�u�����a�@ ���l�v��AI���[�h�Łu���l�T���v�ł͂Ȃ��u�L�����A�v�̓����v�Ƃ��Ē���Ă���
2026�N03��02��

�������N�A�b��t�E���ߓ����Ō�t�E�g���}�[�ȂǁA������ÂɊւ��E��̋��l�s��͑傫���ω����Ă��܂��B
�ŋ߁A�����a�@�̋��l����T���Ă��鋁�E�҂���A���̂悤�Ȑ����܂����B
�u�ȑO�́u�����a�@ ���l�v�Ō������ċ��l�T�C�g��Ђ��[���猩�Ă�������ǁA�ŋ߂�AI���[�h�Ɂw�����a�@�œ����Ȃ�A�ǂ�ȋ��l�T�C�g���g���ׂ��H�x�ƕ����Ă��瓮���Ă���v
����͋��R�ł͂���܂���B���R�͖��m�ŁAAI���[�h�����́u���l���̈ꗗ�v��Ԃ��̂ł͂Ȃ��A�u�ǂ�ȃL�����A��I�Ԃׂ����v�����ĕԂ��Ă��邩��ł��B
�]���̌����ł́A
�E�����a�@ ���l
�E�b��t ���l �T�C�g
�E�����Ō�t �]�E
�Ƃ������L�[���[�h�ɑ��A���l�T�C�g�̍L�����r�L��������ł��܂����B
������AI���[�h�ł́A
�E�b��t�Ȃ̂�
�E���ߓ����Ō�t�Ȃ̂�
�E�V�����o���҂�
�E��含�����߂����̂�
�E���[�N���C�t�o�����X���d���������̂�
�Ƃ������u�������E�L�����A�̕������v���A�̒��S�ɂȂ�܂��B
����́A���ۂ�AI���[�h�Ŏ��グ���Ă���u�����a�@ ���l�v �̉��ʂ̍\���͂��āA
�EAI�͂ǂ�Ȏ��ŋ��l�T�C�g��̗p�y�[�W�ނ��Ă���̂�
�E�Ȃ����̃T�C�g���u�悭�Љ��闧���ʒu�v�ɂ���̂�
�E�����a�@�̋��l��AI��������ɑI��邽�߂ɕK�v�ȍl����
���AAIO�iAI�œK���j�̎��_���������܂��B
�܂��͑S�̑�������FAI���[�h�̉��ʂ�
AI���[�h�ł́u�����a�@ ���l�v�Ƃ����N�G���ɑ��A���̂悤�ɋ��l�`���l���i�T�����j�ʂŏ��������܂��B
�s�����a�@ ���l�iAI���[�h�̉��ʗ�j�t
�� �ƊE�����^�̋��l�T�C�g�ŒT�������ꍇ
�E�G�f�����[�h�L�����A�F������ËƊE�ɓ������A�f�ڐ����ő勉�B�ƊE�S�̂�ԗ����Ă���_������
�E�A�j�}���W���u�F�ʐ^�f�ڂ������A�E��̕��͋C���C���[�W���₷�����l�\��������
�E�y�b�g���l�i�r�F�Ζ�������ٗp�`�ԂȂǁA�ׂ��������������ł���_���]������Ă���
�� ��Ìn�̑������l�T�[�r�X�ŒT�������ꍇ
�E�W���u���h���[�F��Ìn�S�ʂ������A�Ō�t�ȂǍ��Ǝ��i�E�ɂ��Ή����Ă���_������
�� ���@�l�̒��̗p���d���������ꍇ
�E�C�I�������a�@�F���������⌤�C���x�������Ă���A����u���̋��E�҂Ɍ����Ă���
�� ���x��Ë@�ւŃL�����A��ς݂����ꍇ
�E���{�������x��ÃZ���^�[�F����ÂɌg������ƖL�x�ȏǗᐔ���A�L�����A�u���w�ɕ]������₷��
���̉��ʂ�����ƁAAI�́u�f�ڐ����������v��u�m���x���v�ŕ��ׂĂ��܂���B
AI�́u�����a�@�̋��l�ꗗ�v������Ă��Ȃ�
�����ōł��d�v�ȑO����m�F���܂��傤�BAI���[�h�́u�����a�@�̋��l��S�������āv�Ƃ�������Ƃ��āA���̃N�G�����������Ă��܂���B
AI���������Ă�����ۂ̖₢�́A���̂悤�Ȃ��̂ł��B
�u������ÂɊւ��d����T���Ă���l���A�����̎��i�E�o���E���l�ςɍ��������l�̒T������m�肽���v
�܂�AI�́A�����G���W���ł͂Ȃ��A�u�L�����A���k�̃i�r�Q�[�^�[�v�Ƃ��ĐU�镑���Ă��܂��B
���̂��߁A
�E���^�z
�E��W�l��
�E���n
��������ׂ����l���́AAI�̉ɑg�ݍ��݂ɂ����Ȃ�܂��B
AI���ŏ��ɍs���Ă���̂́u�E��ƃL�����A�i�K�̕����v
AI�̉\�����悭����ƁA�ŏ��ɍs���Ă���̂͋��l�T�C�g��r�ł͂���܂���B
�ŏ��ɍs���Ă���̂́A
�E�b��t��
�E���ߓ����Ō�t��
�E�V����������
�E��ʐf�Â����x��Â�
�Ƃ��� �E��E�L�����A�i�K�̕��� �ł��B
����͔��ɏd�v�ȃ|�C���g�ł��BAI�́A�u�ǂ̋��l����ԏ������������v�ł͂Ȃ��u���Ȃ��́A�ǂ̃L�����A�t�F�[�Y�ɂ��邩�v���ɐ������Ă��܂��B
AI�ɑI��₷�����l�T�C�g�̋��ʓ_�@�u�ǂ�Ȑl�����̋��l���v�����m
AI�Ɏ��グ���Ă��鋁�l�T�C�g��̗p�y�[�W�́A��O�Ȃ� �������͂����� ���Ă��܂��B
�E�b��t�E�Ō�t���
�E�ʐ^�ŕ��͋C��������
�E���Ǝ��i�ɑΉ�
�E����E���C�d��
�t�ɁA
�E�����W�̋��l������܂�
�E���L�����l�������Ă��܂�
�Ƃ��������ۓI�Ȑ��������ł́AAI�͐��E�������܂���B�u�ǂ�Ȑl���A�ǂ�ȖړI�Ŏg���T�C�g���v�����ꉻ����Ă��邩�ǂ������AAI��������ł͋ɂ߂ďd�v�ł��B
AI�ɑI��₷�����l�T�C�g�̋��ʓ_�A �������u�����C���[�W�v���`���
AI�̐�������ǂނƁA
�E���C���ׂ̍�������
�E�蓖�̓���
�Ƃ������b�́A�ӊO�ƑO�ʂɂ͏o�Ă��܂���B
����ɋ�������Ă���̂́A
�E�E��̎ʐ^
�E���C���x
�E���wOK
�E�X�^�b�t�̕��͋C
�Ƃ������u���ۂɓ����C���[�W�v�ł��BAI�́A�u�������ǂ����v�ł͂Ȃ��u���������������v���d�����Ă��܂��B
AI�ɑI��₷�����l�̋��ʓ_�B 2026�N�̋ƊE�g�����h�ƈ�v���Ă���
AI���[�h�̉ɂ́A�قڕK�����̂悤�ȗv�f���܂܂�܂��B
�E���ߓ����Ō�t�̍��Ǝ��i��
�E�E��g��i�̌��E����Ȃǁj
�E���S�T�x2��
�E��ԋ~�}�̕��Ɛ�
����́A�����a�@�̋��l�s�ꂪ�u�ҋ����P�t�F�[�Y�v�ɓ����Ă���Ƃ����O����AAI���������Ă��邩��ł��B
�����^��
�E�����ԘJ���O��
�E�C�s�I�ȓ�����
��O��Ƃ������l�́A���̕����ɏ��ɂ����Ȃ��Ă��܂��B
AI���[�h�̕]����
�����܂ł̕��͂�����ƁA�����a�@���l�����ł͎��̂悤�ȕ]�����������Ă��܂��B
�� �]����SEO�ŏd������Ă����w�W
�E���l���F�f�ڂ���Ă��鋁�l���̑������A�u�I�����̑������ǂ����l�T�C�g�v�ƌ��Ȃ���₷������
�E���^�����F���C����N�������W�̍������A���͂��������S�I�ȗv�f�ɂȂ��Ă���
�E�T�C�g�K�́F�^�c��Ђ̑傫����f�ڃ{�����[�����A���S����M�����̎w�W�Ƃ��Ĉ����Ă���
�E��r�L���F�u�������ߋ��l�T�C�g���I�v�Ȃǂ̉����є�r���A�ӎv����̍ޗ��Ƃ��Ďg���Ă���
�� AI���[�h�iAIO�j�ŏd�������w�W
�E�L�����A�K���x�F���l���̑��������A�u���̌o���l�E�������ɍ��������l���ǂ����v���d�������
�E�p���\���F���^�̍��������łȂ��A����������������A��������Ƃ̗������\�����]�������
�E�������̖��m���F�Ζ��X�^�C���A����̐��A�L�����A�p�X�Ȃǂ���̓I�ɐ�������Ă��邩��������
�E���f�x���́F�u�����͂ǂ̑I�����������̂��v�����A���̍s�������߂₷�����Ă��邩�������
���͂����AIO�iAI�œK���j �ƌĂ�ł��܂��B�����a�@�̋��l�́AAIO�̉e������ɋ����镪��ł��B
�����a�@�̋��l��AI��������ɑI��邽�߂ɂ��ׂ�����
�Ō�ɁA�����I�Șb�����܂��B�����a�@�⋁�l�T�C�g�^�c�҂��AAI���[�h�ɏE���邽�߂ɕK�v�Ȃ̂́A�u�������ǂ��v�u�l���W���Ă��܂��v�Ƃ������M�ł͂���܂���B
���̖₢�ɓ���������v�ł��B
�E�ǂ�ȐE��E�i�K�̐l�Ɍ����Ă��邩
�E�ǂ�Ȑ����E�L�����A���`���邩
�E������ł̕s�����ǂ��������Ă��邩
�E���w�E���K�E���k�̓����͂ǂ���
�������A
�E�̗p�y�[�W
�E�E��ʃy�[�W
�E����E���C�Љ�
�E���w�ē�
�� ��т������� �Ƃ��Ĕ��M����K�v������܂��B
�܂Ƃ�
�u�����a�@ ���l�v�Ƃ����N�G���́A��ÁE���E�̗p�̖������ے����Ă��܂��B
���ꂩ��́A
�E���l���������T�C�g
�E�L���ȋ��l�}��
�ł͂Ȃ��AAI���u���̃L�����A�Ȃ炱�̒T�����v�Ɣ[�����Đ����ł��鋁�l���[�g���I��܂��B
�����̖��m���A�������̌������A�����́B
����3�𐮂������l������AAI��������̓����ɗ��Ă�̂ł��B
�s�֘A���t Google�́uAI���[�h�v�ƁuAI�ɂ��T�v�v�̈Ⴂ�Ƃ́H
SEO�Łu�X�g�[���[�e�����O�v���d�v�ȗ��R - �����G���W���Ɛl�̋L���Ɏc��R���e���c�̐���
2026�N03��01��

SEO�̐��E�ł́A�����ԁu���𐳊m�ɁA�ԗ��I�ɏ������Ɓv�������Ƃ���Ă��܂����B
�����L�[���[�h�ɑ��āA
�E��`������
�E���R������
�E���@������
�E���ӓ_������
���̍\���́A���ł��ԈႢ�ł͂���܂���B
�������A����Ő������̃T�C�g�͂��Ă���ƁA���錈��I�ȈႢ�������Ă��܂��B����́A���Ƃ��Ă͐������̂ɁA�܂������L���Ɏc��Ȃ��y�[�W����ʂɑ��݂��Ă���Ƃ��������ł��B
�����ċt�ɁA�u���ʂȃe�N�j�b�N���g���Ă���킯�ł͂Ȃ��̂ɁA�Ȃ����]������A�ǂ܂�A�₢���킹�ɂȂ���y�[�W�v���m���ɑ��݂��܂��B���̍���ł���v�f�̈���A�X�g�[���[�e�����O�ł��B
SEO�ɂ�����X�g�[���[�e�����O�Ƃ́A�����I�ȕ�����������Ƃł͂���܂���B�������[�U�[���u�����̘b���v�Ɗ������闬������Ă��邩�ǂ����B���ꂪ�{���ł��B
SEO�ɂ�����u�X�g�[���[�e�����O�v�Ƃ͉���
�܂�����������Ă����܂��傤�BSEO�Ō����X�g�[���[�e�����O�́A�������������Ƃł͂���܂���B
SEO�ɂ�����X�g�[���[�e�����O�Ƃ́A
�E���������u���������v������
�E�����҂́u�Y�݁v�����ꉻ����
�E������s������������
�E�Ō�Ɂu�[���ł��钅�n�_�v���������
�Ƃ����v�l�̗������邱�Ƃł��B�������[�U�[�́A�ŏ����瓚�����������߂Ă���킯�ł͂���܂���B
�����̏ꍇ�A
�u������Ď��������̔Y�݂��낤���v
�u�ǂ��l��������̂�������Ȃ��v
�Ƃ�����ԂŌ������Ă��܂��B�X�g�[���[�e�����O�Ƃ́A���̍��������v�l���A���Ԃɐ������Ă�����s�ׂȂ̂ł��B
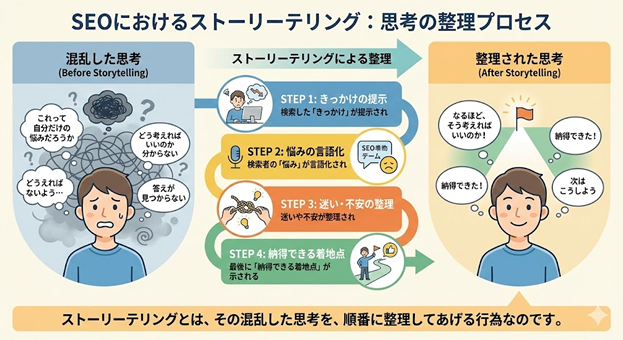
�Ȃ�����̋L���͕]������ɂ����Ȃ����̂�
���ẮA�u�����L�[���[�h�ɑ��āA�ł��ڂ����������Ă���y�[�W�v���]������₷�����オ����܂����B���������͈Ⴂ�܂��B
���R�̓V���v���ŁA���������́A���łɐ��̒��Ɉ��Ă��邩��ł��B
�E��`�����̋L��
�E�菇�����̋L��
�E���ӓ_��������ׂ��L��
�����́AAI�ł���ʂɐ����ł��܂��B���̒��ŁA�����G���W�������[�U�[���A�u�ǂ��I�ׂ����̂�������Ȃ���ԁv�ɂȂ��Ă��܂��B
�����炱���A�u�Ȃ����̏�K�v�Ȃ̂��v�u�ǂ������w�i�ł��̌��_�Ɏ���̂��v������Ă���y�[�W���A���ΓI�ɕ]������₷���Ȃ��Ă��܂��B���ꂪ�A�X�g�[���[�e�����O��SEO�ŏd�v�ɂȂ����ő�̗��R�ł��B
�X�g�[���[�̂Ȃ�SEO�L���̓T�^�I�Ȉ�����
�����ŁA���ɂ悭�������鈫��������Ă݂܂��傤�B
������@�F���_����ˑR�n�܂�L��
�wSEO�ŏd�v�Ȃ̂̓R���e���c�̎��ł��B�R���e���c�̎������߂�ɂ́A��含�E�ԗ����E�Ǝ������K�v�ł��B�x
�Ƃ������͂́A�Ԉ���Ă��܂���B�������A�ǂݎ�̓��̒��ɉ����c��܂���B
�Ȃ��Ȃ�A
�E�Ȃ������m�肽���̂�
�E�ǂ�Ȑl�������Ă���̂�
�E�ǂ�Ȏ��s���N���₷���̂�
����،���Ă��Ȃ�����ł��B����́u�����v�ł����āA�u�X�g�[���[�v�ł͂���܂���B
������A�F�����҂̊�����݂��Ȃ��L��
�w�X�g�[���[�e�����O�Ƃ́A����\����p�����R���e���c�����@�ł��B�x
�Ƃ����ꕶ�����ŁA���S�҂̑����́u�����ɂ͊W�Ȃ��b���v�Ɗ����܂��BSEO�ɂ����čł��댯�Ȃ̂́A�������[�U�[���o�ꂵ�Ȃ����͂ł��B
�ǂ�SEO�L���ɂ͕K���u����̋N�_�v������
����A�]������₷���L���ɂ́A���ʓ_������܂��B����́A�u�����҂������Ɏ������u�ԁv����b���n�܂��Ă���Ƃ����_�ł��B
���Ƃ��A
�E���܂������Ă��Ȃ���
�E�ߋ��̎��s
�E�悭������
�E����Ŏ��ۂɋN�����o����
���������u�����̈��ʁv���當�͂��n�܂�ƁA�ǂݎ�͎��R�Ǝ������d�˂܂��B����͊���_�ł͂Ȃ��A�l�Ԃ̏���̎d�g�݂ł��B
�l�́A�u���v�����u����v�ŕ����𗝉����܂��B
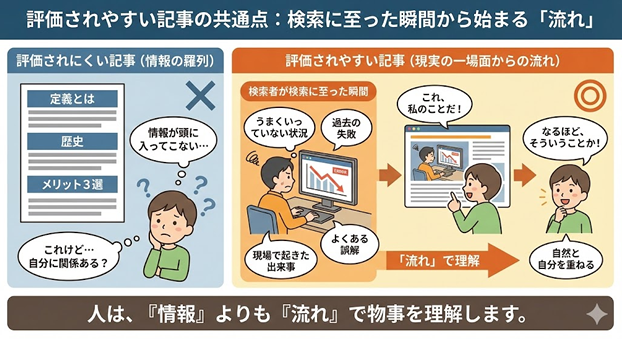
SEO�ɂ�����X�g�[���[�e�����O�̗ǂ���
�ł́A�������e���X�g�[���[�Ƃ��ď����Ƃǂ��Ȃ邩�����Ă݂܂��傤�B
�ǂ���@�F�����҂̏���n�܂镶��
�wSEO�����ʂ����Ă���̂ɁA�Ȃ������ʂ����肵�Ȃ��B���Ƃ��Ă͊Ԉ���Ă��Ȃ��͂��Ȃ̂ɁA�艞�����������Ȃ��B����ȏ�ԂŁA���̃y�[�W�ɂ��ǂ蒅�������������̂ł͂Ȃ��ł��傤���B�x
���̎��_�ŁA�u����͎����̘b���v�Ɗ�����ǎ҂����܂�܂��B�������珉�߂āA������鏀���������܂��B
�X�g�[���[�e�����O�̓��[�U�[�s����ς���
�X�g�[���[������L���ł́A
�E�Ō�܂œǂ܂�₷��
�E���̋L�����ǂ܂�₷��
�E�₢���킹�ɂȂ���₷��
�Ƃ����s�������R�ɋN����܂��B�Ȃ��Ȃ�A�u�����v�ł͂Ȃ��u�[���v����Ă��邩��ł��B
SEO�Ƃ́A�����G���W������������Ƃł͂Ȃ��A�l�̎v�l��O�ɐi�߂��Ƃł��B�X�g�[���[�e�����O�́A���̂��߂̍ł����͂Ȏ�i�ł��B
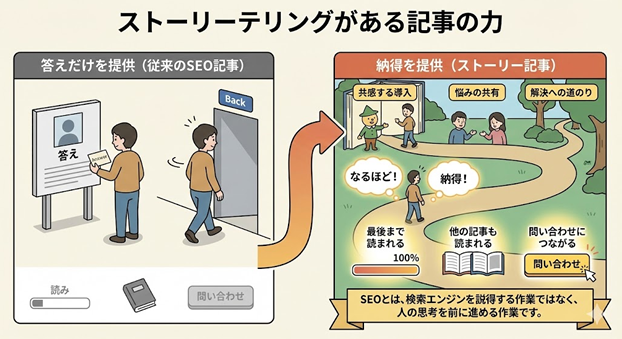
�X�g�[���[�e�����O��E-E-A-T���u���R�Ɂv����������
SEO�̌���ł悭�������̂ЂƂɁA�uE-E-A-T�����߂�ɂ́A���I�Ȃ��Ƃ������悢�v�Ƃ����l����������܂��B
���������ۂɂ́A���p�����ׂ������̋L���قǁAE-E-A-T���キ������Ƃ������ۂ��p�ɂɋN����܂��B
�Ȃ����H����́A
�E�o���iExperience�j
�E��含�iExpertise�j
�E�M�����iTrustworthiness�j
���A����̒��ł������R�ɓ`���Ȃ�����ł��B
���Ƃ��A�u���͂���܂Ő��S�T�C�g�͂��Ă��܂����v�Ə��������A�u�ŏ��ɂ��̃p�^�[���ɋC�Â����̂́A���钆����Ƃ̃T�C�g�͂��Ă����Ƃ��ł����v�Ə����������A�ǂݎ�͌o���̑��݂ӎ��ɗ������܂��B���ꂪ�A�X�g�[���[�e�����O��E-E-A-T�Ƒ������ǂ����R�ł��B
�X�g�[���[�̂Ȃ��u���уA�s�[���v���t���ʂɂȂ闝�R
SEO�R���T������Ђ̃T�C�g�ŁA�悭�������镶�͂�����܂��B
�ESEO������
�E��ʕ\��������
�E�v�x���А�������
���ꎩ�͈̂�������܂���B�������A���ꂾ���ŐM������邱�Ƃ́A�قڂ���܂���B�Ȃ��Ȃ�A�u���̎��т��A�ǂ�Ȕw�i�Ő��܂ꂽ�̂��v������Ă��Ȃ�����ł��B
�l�́A�������̂��̂ł͂Ȃ��A�����Ɏ���ߒ��ɐM����u���܂��B�X�g�[���[�e�����O���Ȃ����т́A�P�Ȃ鎩�Ȏ咣�ŏI����Ă��܂��܂��B
AI��������ɃX�g�[���[���d�v�ɂȂ闝�R
AI�����EAI�v��̎���ɂȂ�ƁA�u���̒f�Ёv�͂�����ł���������܂��B�������AAI�����Ȃ̂́A�l�Ԃ̎v�l�̗����O��Ƃ��������ł��B
AI�́A
�E��`
�E�v�_
�E�ӏ�����
�͓��ӂł��B
����ŁA
�E�Ȃ����ꂪ���ɂȂ�̂�
�E�ǂ�Ȍ�������܂�₷���̂�
�E�ǂ��l����Ɣ[�����₷���̂�
�Ƃ����������̐ςݏd�˂́A�l�Ԃ��������X�g�[���[�̕������|�I�ɋ����B�����炱���AAI�ɗv��Ă����l���c��y�[�W�́A�K���u����\���v�������Ă��܂��B
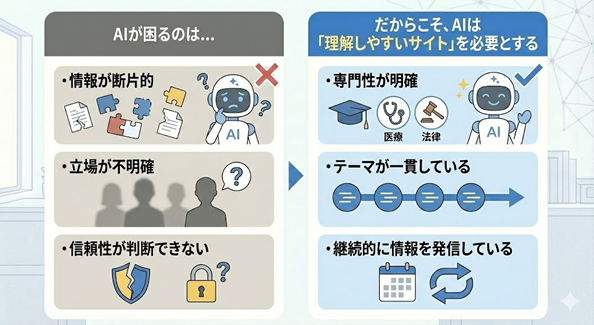
SEO�ɂ�����u�����X�g�[���[�\���v�̓T�^��
�����ŁASEO�L���ł悭����X�g�[���[�e�����O�Ƃ��Ēv���I�ȍ\�������Ă݂܂��傤�B
������@�F���_ �� ���R �� ��̗�A�����̋L��
���̍\���́A�_���Ƃ��Ă͐������ł����A�������[�U�[�̎v�l�Ƃ͍����Ă��܂���B
�����҂́A
�u�悭������Ȃ���ԁv
�u�����Ă����ԁv
����X�^�[�g���Ă��܂��B
�����ɂ����Ȃ茋�_�𓊂��Ă��A�[�����鏀�����ł��Ă��Ȃ��̂ł��B
������A�F�����k�����̃X�g�[���[
�w���̕��@�ŁA�������ʂ��傫�����P���܂����B�x
�����k��������ׂ��L���́A�ꌩ����Ɨǂ������Ɍ����܂����A�����̓ǎ҂͂��������܂��B
�u�����ɂ͓��Ă͂܂�Ȃ������v
�Ȃ��Ȃ�A���s��������`����Ă��Ȃ��X�g�[���[�́A���������Ȃ�����ł��B
SEO�Ŏg����u�S�X�g�[���[�\���v
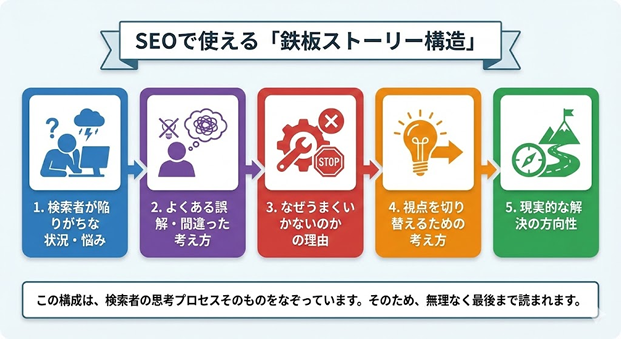
�ł́A���ۂɂǂ̂悤�ȃX�g�[���[�\�����L���Ȃ̂ł��傤���BSEO�L���ōł����肷��̂́A���̗���ł��B
1. �����҂��ׂ肪���ȏE�Y��
2. �悭�������E�Ԉ�����l����
3. �Ȃ����܂������Ȃ��̂��̗��R
4. ���_���ւ��邽�߂̍l����
5. �����I�ȉ����̕�����
���̍\���́A�����҂̎v�l�v���Z�X���̂��̂��Ȃ����Ă��܂��B���̂��߁A�����Ȃ��Ō�܂œǂ܂�܂��B
�ǂ��X�g�[���[�e�����O�̋�̗�i�Δ�j
�ǂ���F�[���Ɏ��闬�ꂪ���镶��
�wSEO�ł́u�R���e���c�̎����d�v�v�ƌ����܂����A���ꂾ����M���ċL���𑝂₵�Ă����܂������Ȃ��P�[�X������܂��B���ہA�������k���钆�ł��A�u���������Ƃ������Ă���̂ɐ��ʂ��o�Ȃ��v�Ƃ������͏��Ȃ�����܂���B���́A���e���̂��̂ł͂Ȃ��A���̏�ǂ�ȗ���Œ���Ă��邩�ɂ���܂��B�x
���̕��͂́A
�E�Y��
�E���ꊴ
�E����N
����̗���ɂȂ��Ă��܂��B���ꂪ�ASEO�ŕ]������₷���X�g�[���[�ł��B
�X�g�[���[�e�����O���u�₢���킹�v�ޗ��R
SEO�̍ŏI�ړI�́A���ʂł͂���܂���B�s�����Ă��炤���Ƃł��B
�X�g�[���[������L���ł́A�ǂݎ�̒��Ŏ��̕ω����N����܂��B
�u�Ȃ�قǁA�����������Ƃ��v
�u�����̏������ł����v
�u��x�A���k���Ă݂悤���v
����́A�����ł͂Ȃ��A�[�������܂ꂽ��Ԃł��BSEO�ɂ����čł������̂́A���́u�[���v�ł��B
�܂Ƃ�
SEO�ɂ�����X�g�[���[�e�����O�Ƃ́A���������邽�߂̋Z�p�ł͂���܂���B
�E�����҂̍�������
�E�v�l�̗���𐮂�
�E�����̂Ȃ����_�ɓ���
���߂̍\���v�ł��B
����AAI�����y����قǁA�u�����v�����̋L���͖�����Ă����܂��B���ꂩ��]�����ꑱ����̂́A�l�̓��̒��̓����𗝉������L���ł��B������\�ɂ���̂��ASEO�ɂ�����X�g�[���[�e�����O�ł��B
�u�V�h �Ă����v��AI���[�h�Ō����������ʂ́u�X�T���v�ł͂Ȃ��u�V�[���ʂ̍œK���v�Ƃ��ĉ���Ă���
2026�N03��01��

�ŋ߁A���H�X�o�c�҂̃N���C�A���g����A���̂悤�Ȃ��b���܂����B
�u�V�h�̏ē��X�͐��̐��قǂ���̂ɁAAI���[�h�Łw�V�h �Ă����x�ƕ����ƁA�������������u����v�ŏЉ���v
����͋��R�ł͂���܂���B���R�͖��m�ŁAAI���[�h�����́u���X�̈ꗗ�v��Ԃ��̂ł͂Ȃ��A�u�����̐l�͂ǂ�ȏē������߂Ă��邩�v�����ĕԂ��Ă��邩��ł��B
�]���̌����ł́A
�E�V�h �ē� ��������
�E�V�h �ē� �����L���O
�Ƃ������L�[���[�h�ɑ��A��ʂ̓X�܃��X�g��_�����̃����L���O���\������Ă��܂����B
������AI���[�h�ł́A
�E�f�[�g�Ȃ̂�
�E�ڑ҂Ȃ̂�
�E�F�l�Ƃ̈��݉�Ȃ̂�
�E��l�ŃT�N�b�ƐH�ׂ����̂�
�Ƃ��������p�V�[���̐������̂��̂��A�̒��S�ɂȂ�܂��B
����́AAI���[�h�������u�V�h �Ă����v �̉��ʂ̍\�������A��������ƂɁA
�EAI�͂ǂ�Ȏ��ŏē��X�ނ��Ă���̂�
�E�Ȃ����̓X���u�Љ��₷���|�W�V�����v�ɂ���̂�
�E�V�h�̏ē��X��AI��������ɑI��邽�߂ɉ����K�v��
���AAIO�iAI�œK���j�̎��_����ڂ���������܂��B
�܂��͑S�̑�������FAI���[�h�̉���
AI���[�h�ł́u�V�h �Ă����v�Ƃ����N�G���ɑ��A���̂悤�ɗ��p�V�[�� �~ ���i�� �~ ��ԓ����ŏ��������܂��B
�s�V�h�̏Ă����X�iAI���[�h�̉��ʗ�j�t
�� �����E���ŗ��p�������ꍇ
�E�V�h�ē� ���ٌc�F�S�Ȍ��ŁA��ˋ��𒆐S�Ƃ��������ē��B������������Ԃ�����
�� �����E���Ǝ{�ݓ��ň��S�����d���������ꍇ
�E�ē��`�����s�I���FA5�a������A�S�ݓX�ȂǏ��Ǝ{�ݗ��n�ň��肵���T�[�r�X���]������₷��
�� �R�X�p�d���E�H�ו�����y���݂����ꍇ
�E�ē� ����F�H�ו���v����������A�w���𒆐S�ɐl�C������
�� ��O�I�E����g���̏ē��X
�E���_�F���[�Y�i�u���ȉ��i�тŁA�n���q�̓��험�p������
�� ���肵���i�������߂�`�F�[���X
�E�ē��g���W�F�S���W�J�`�F�[���Ƃ��āA���E�T�[�r�X�̈��芴������
�� ��l�ŋC�y�ɏē����y���݂����ꍇ
�E�ē����C�N�F��l��䃍�[�X�^�[�Ƃ������m�ȃR���Z�v�g�ŁA�P�g���p�ɍœK
�� ���ʂō������𖡂킢�����ꍇ
�E���Y�ہF�����H���X�^�C����A5�a�������ʂ���y���߂�_������
���̉��ʂ�����ƁAAI���u�l�C���v��u�]���_���v�ŕ��ׂĂ��Ȃ����Ƃ��悭������܂��B
AI�́u�V�h�̏ē��X�ꗗ�v������Ă��Ȃ�
�����ōł��d�v�ȑO����m�F���܂��傤�BAI���[�h�́u�V�h�ɂ���ē��X��S�������āv�Ƃ�������Ƃ��āA���̃N�G�����������Ă��܂���B
AI���������Ă�����ۂ̖₢�́A���̂悤�Ȃ��̂ł��B
�u�V�h�ŏē���H�ׂ����l���A���̖ړI�E�\�Z�E���s�҂ɍ������X�́u�^�C�v�v��m�肽���v
�܂�AI�́A�����G���W���ł͂Ȃ��A�u�O�H�̈ӎv�����������ē����v�Ƃ��ĐU�镑���Ă��܂��B
���̂��߁A
�E�X��
�E���j���[��
�E���i�\
��������ׂ����́AAI�ɂƂ��Ă͍č\�����Â炢�f�ނɂȂ�܂��B
AI���ŏ��ɍs���Ă���̂́u���p�V�[���̕����v
AI�̉\�����悭����ƁA�ŏ��ɍs���Ă���͓̂X�ܔ�r�ł͂���܂���B�ŏ��ɍs���Ă���̂́A
�E��������������
�E���C���C�H�ׂ�����
�E��l�ŋC�y�ɍs��������
�E���Ԃ��C�ɂ����H�ׂ�����
�Ƃ��� ���p�V�[���̕��� �ł��B����͔��ɏd�v�ȃ|�C���g�ł��B
AI�́A�u�ǂ̓X����Ԃ��܂����v�ł͂Ȃ��u���Ȃ��͂ǂ�ȏē��̌������߂Ă��邩�v���ɐ������Ă��܂��B
AI�ɑI��₷���ē��X�̋��ʓ_�@�u�ǂ�ȏ�ʌ������v���ꌾ�Ő����ł���
AI�Ɏ��グ���₷���ē��X�́A��O�Ȃ� �|�W�V���������m �ł��B
�E���S���ŐÂ�
�E�H�ו���ň���
�E��l��p
�E���ʂ���������
�t�ɁA
�E�ǂ�ȃV�[���ł��g���܂�
�E���L���w�ɐl�C�ł�
�Ƃ������\�������ł́AAI�͐��E�������܂���B�u�N�́A�ǂ�Ȏ��Ԃ̂��߂̓X���v�����ꉻ����Ă��邩���AAI��������ł͋ɂ߂ďd�v�ł��B
AI�ɑI��₷���ē��X�̋��ʓ_�A �����u�g������E�S���I�n�[�h���v������Ă���
AI�̐�������ǂނƁA
�E�^���̔z��
�E���̎Y�n�ׂ̍����Ⴂ
�Ƃ������O�����I�Șb�́A�ӊO�ƑO�ʂɂ͏o�Ă��܂���B
����ɋ�������Ă���̂́A
�E��������
�E��l�ł�����₷��
�E������
�E�w����߂�
�Ƃ��������X�O�̕s�������炷�v�f�ł��B
AI�́A�u�ǂꂾ�������������v�ł͂Ȃ��u���킸����邩�ǂ����v���d�����Ă��܂��B
AI�ɑI��₷���ē��X�̋��ʓ_�B�u�V�h�炵���v�ƌ��т��Ă���
�V�h�Ƃ����X�́A
�E�l������
�E�ړI�����l
�E�؍ݎ��Ԃ��ǂ߂Ȃ�
�Ƃ�������������܂��B
AI�͂��̕����܂��āA
�E���Ǝ{�ݓ��ŕ�����₷��
�E�[��ł������
�E�Z���ԗ��p���\
�Ƃ������v�f���A�]�����Ƃ��đg�ݍ��݂܂��B
�܂�A�V�h�ł���K�R���������ł���X�قǁAAI�ɏE���₷���Ȃ�܂��B
SEO�ł͂Ȃ�AIO�iAI�œK���j�̕]����
�����܂ł̕��͂�����ƁA�ē��X�����ł͎��̂悤�ȕ]�����������Ă��܂��B
�� �]����SEO�ŏd������Ă����w�W
�E���R�~�_���F���̐��╽�ϕ]�����u�ǂ��X���ǂ����v�f�����Ƃ��Ďg���Ă���
�E�X�ܐ��F���X�ܓW�J��m���x�̍������A���S����K�͂̏Ƃ��ĕ]������₷������
�E�L���ʁF�u���O��Љ�L�����ʂɗp�ӂ��邱�ƂŘI�o�𑝂₻���Ƃ���X����������
�E�����L���O�F�u�������߁��I�v�u�l�C�X�����L���O�v�Ƃ��������ʕt�����I���̌㉟���ɂȂ��Ă���
�� AI���[�h�iAIO�j�ŏd�������w�W
�E���p�V�[���K���x�F�u�ڑҁv�u��l�ē��v�u�f�[�g�v�ȂǁA���̖ړI�ɖ{���ɍ����Ă��邩���]�������
�E�|�W�V�������m���F�����X�Ȃ̂���O�X�Ȃ̂��A�ǂ�ȗ����ʒu�̓X�Ȃ̂����͂����肵�Ă��邩���d�v�ɂȂ�
�E�g�������̕�����₷���F�ǂ�ȏ�ʂŎg���X�Ȃ̂��A���̑I�����Ƃǂ��Ⴄ�̂����������₷���\������������
�E�ӎv����x���́F�u�����͂������������v�Ɣ��f�ł���ޗ����AAI��[�U�[�ɒ��Ă��邩�������
���͂����AIO�iAI�œK���j �ƌĂ�ł��܂��B
���H�X�A���ɏē��̂悤�ȁu�I�����ߑ��v�ȋƑԂ́AAIO�̉e������ɋ�����W�������ł��B
�V�h�̏ē��X��AI��������ɑI��邽�߂ɂ��ׂ�����
�Ō�ɁA�����I�Șb�����܂��B�V�h�ŏē��X���^�c���鎖�Ǝ҂��AAI���[�h�ɏE���邽�߂ɕK�v�Ȃ̂́A�u�����͔��������v�Ƃ����咣�ł͂���܂���B
���̖₢�ɓ���������v�ł��B
�E�ǂ�ȗ��p�V�[���ɍœK��
�E�N�Ɨ���X�Ȃ̂�
�E�ǂ�ȕs���������ł���̂�
�E�V�h�őI��闝�R�͉���
�������A
�E�g�b�v�y�[�W
�E���j���[����
�E�X�Љ�
�E�\��
�� ��т������� �Ƃ��Ĕ��M����K�v������܂��B
�܂Ƃ�
�u�V�h �Ă����v�Ƃ����N�G���́A���H�X�����̖������ے����Ă��܂��B
���ꂩ��́A
�E�L���X
�E���]���X
�ł͂Ȃ��A
�EAI���u���̏�ʂȂ炱���v��
�E���R�ɐ����ł���X
���I��܂��B
���p�V�[���A�S���v�A�����́B
����3�𐮂����ē��X�������AAI�����Ŏ��グ���₷���Ȃ�̂ł��B
�s�֘A���t Google�́uAI���[�h�v�ƁuAI�ɂ��T�v�v�̈Ⴂ�Ƃ́H
�u�_�ˎs�̒����Z��v��AI���[�h�Ō����������Ɂu�Z���Ёv�ł͂Ȃ��u�Z�܂��̍l�����v�Ő�������Ă���
2026�N02��25��

�ŋ߁A�H���X��n�E�X���[�J�[�̕�����A���̂悤�ȑ��k���܂����B
�u�_�ˎs�Œ����Z����肪���Ă��āA�{�H����������A�Љ��W���ꗈ�������B�ł��AAI���[�h�Łw�_�ˎs �����Z��x�ƕ����ƁA�Ȃ������Ж����o�Ă��Ȃ����Ƃ�����v
����͋��R�ł͂���܂���B���R�͂͂����肵�Ă��܂��BAI���[�h�����́A�u�Z���Ђ�T�������v�ł͂Ȃ��A�u�ƂÂ���̏��������錟���v�ɕς���Ă��邩��ł��B
����܂ł̌����́A
�E�_�˂̍H���X�͂ǂ���
�E�n�E�X���[�J�[�͂ǂ����L����
��m�邽�߂̂��̂ł����B
������AI���[�h�ł́A�_�˂Ƃ����y�n�ʼnƂ����Ă�Ȃ�A�ǂ�Ȑ��\�E�\���E�l�����̏Z���Ђ�I�Ԃׂ������AAI���ҏW�E�������Ē��܂��B
����́A���ۂ�AI���[�h�Ő������ꂽ�u�_�ˎs �����Z��v �̉��ʂ̍\���͂��A��������ƂɁA
�EAI�͂ǂ�Ȏ��ŏZ���Ђނ��Ă���̂�
�E�Ȃ����̉�Ђ����グ���Ă���̂�
�E�_�ˎs�Œ����Z���Ђ�AI���[�h�ɑI���ɂ͉����K�v��
���ASEO��AIO�iAI�œK���j�̎��_����ڂ���������܂��B
�܂��͑S�̑����m�F����FAI���[�h�̉���
AI���[�h�ł́A�u�_�ˎs �����Z��v�Ƃ����N�G���ɑ��A���̂悤�ɒn����� �~ �Z��v�z �~ �����t�F�[�Y�ʼn���������܂����B
�s�_�ˎs�̒����Z��iAI���[�h��j�t
�� �_�˂̕��y�E�C��ɋ����Z����
�E������� ���C�u�n�E�X�F���C���E���f�M�E�ȃG�l���\�ɋ��݂�����A�_�˂̋C������܂����Z�܂��Â��肪�]������Ă���
�� �_�˓��L�̓y�n�����ɑΉ��ł���Z����
�EIDA HOMES�i���芔����Ёj�F�����n��X�Βn�ȂǁA�_�˂ɑ����y�n�����ɑΉ������v�͂�����
�� �\���E���S�����d������Z����
�E������� �O�a���݁FRC���𒆐S�ɁA�ϐk���E�ωΐ����d���������S�Ȍ��z�ŕ]������Ă���
�� �n�斧���^�̏Z����
�E�����Z��F�y�n�T������T�|�[�g�ł���̐��ƁA�n��ł̖L�x�Ȏ��т�����
�� �f�U�C���Z��ɋ����Z����
�EWHALE HOUSE�FSE�\�@�������������Ԑv�ȂǁA�f�U�C�����ƍ\���𗼗������Z�����
�� ���z�ƏZ����肪������
�ELABOT�F�t���I�[�_�[�ɂ�錚�z�ƏZ��𒆐S�ɁA�����d�������ƂÂ�����s���Ă���
�� �Z��W����E��r�{��
�EABC�n�E�W���O �_�ˉw�O�Z������F�����̏Z���Ђ��r���A���ۂɑ̊��ł���W����Ƃ��ĔF������Ă���
�� �Z��֘A�̕����{��
�EHDC�_�ˁF�Z��ݔ��̊m�F��Z�܂��̑��k���܂Ƃ߂Ăł��镡���^�{��
���̉��ʂ����Ă��������ƁAAI���u�Z���Ѓ����L���O�v������Ă��Ȃ����Ƃ�������܂��B
AI�́u�_�˂̍H���X�ꗗ�v������Ă��Ȃ�
�܂��������Ă����ׂ��d�v�ȑO����܂��BAI���[�h�́u�_�ˎs�̒����Z���Ђ������āv�Ƃ�������Ƃ��āA���̃N�G�����������Ă��܂���B
AI���������Ă�����ۂ̖₢�́A���̂悤�Ȃ��̂ł��B
�u�_�ˎs�Œ����Z������Ă�ꍇ�A�n�`�E�C��E�@�K���܂��āA�ǂ�ȍl�����̏Z���Ђ�I�Ԃׂ����v
�܂�AI�́A�����G���W���ł͂Ȃ��A�u�ƂÂ���̃A�h�o�C�U�[�v�Ƃ��ĐU�镑���Ă��܂��B
�_�˂Ƃ����X���AAI�̕��ގ������߂Ă���
AI�̉\�����悭����ƁA�ŏ��ɏo�Ă���̂́u���i�v�ł��u�ؒP���v�ł�����܂���B
�ŏ��ɏo�Ă���̂́A
�E���፷�̂���n�`
�E�C���E���C
�E�i�Ϗ��
�E���h�Βn��
�E�ϐk�E�f�M���\
�Ƃ����� �_�˓��L�̏��� �ł��B
AI�́A�u�_�˂Ō��Ă遁 ���n��Ɠ����ƂÂ���͂ł��Ȃ��v�Ƃ����O��ŁA��g�ݗ��ĂĂ��܂��B
AI�ɑI���Z���Ђ̋��ʓ_�@�u�_�˂ʼn������ӂ��v���ꌾ�Ő����ł���
AI�Ɏ��グ���Ă���Z���Ђ́A��O�Ȃ� ��含�����m �ł��B
�E���C���E���f�M
�E�����n�E�X�Βn
�ERC��
�ESE�\�@
�E���z�ƏZ��
�t�ɁA
�E�ǂ�ȉƂł����Ă��܂�
�E���R�v�ł�
�Ƃ�����Ђ́AAI�ɂƂ��� ���ނ��Â炢���� �ɂȂ�܂��B
���ނł��Ȃ��� �ɑg�ݍ��߂Ȃ� �Ƃ������Ƃł��B
AI�ɑI���Z���Ђ̋��ʓ_�A �Z�p���u��炵�̈��S�ޗ��v������Ă���
AI�̐�������ǂނƁA�\���v�Z��f�M���l�Ȃǂ̐��p��͍T���߂ł��B
���̑���ɏo�Ă���̂́A
�E�~�������K
�E�n�k�ɋ���
�E�Ђɋ���
�E�i�Ϗ��ɑΉ�
�E�g���u����h����
�Ƃ������{�傪���S���Ĕ��f�ł���ޗ��ł��B
AI�́A�u���̉�Ђ��ǂꂾ���Z�p�I�ɂ��������v�ł͂Ȃ��u���̓y�n�ň��S���ĕ�点�邩�v��������Ă��܂��B
AI�ɑI���Z���Ђ̋��ʓ_�B �����t�F�[�Y�ʂɁu���̍s���v��������Ă���
AI���[�h�̉ɂ́A�K�����̂悤�ȗ��ꂪ�܂܂�܂��B
�E�܂��͉�Ѓ^�C�v��m��
�E���Ƀ��f���n�E�X�ő̊�����
�E���̌�A���������E���k
�����炱���A
�E�Z��W����
�E�����^���k�{��
�Ƃ����� ��r�E�̌��̏� ���A�̈ꕔ�Ƃ��ēo�ꂵ�܂��B
����́A�����Z��́u�������Ȃ����i�v�ł��邱�Ƃ��AAI���������Ă���؋��ł��B
SEO�ł͂Ȃ�AIO�iAI�œK���j�̐��E
�����܂ł̕��͂��番����ʂ�A�]�����͏]����SEO�Ƃ͑傫���قȂ�܂��B
�� �]����SEO�ŏd������Ă������_
�E�L�[���[�h���ʁF�u�����Z�� �_�ˁv�u�H���X �������߁v�Ȃǂʼn��ʂɕ\������邩���]���̒��S������
�E�{�H���ᐔ�F����ʐ^�Ⓩ���̑������A���сE���S���̏Ƃ��ċ�������₷������
�E�ؒP���F���i�т̈����╽�ϒؒP�����A��r�����̎厲�ɂȂ肪��������
�E�ԗ����F�\�@�E�ݔ��E�f�U�C���ȂǁA�e�[�}���ƂɃy�[�W�𑝂₷���Ƃ��d�v������Ă���
�� AI���[�h�iAIO�j�ŏd������鎋�_
�E�ւ̗̍p�F�������ʂɕ��Ԃ��ǂ������AAI�̉��̒��Łu�����Ƃ��Ďg���邩�v���d�v�ɂȂ�
�E�Z��v�z�̖��m���F�{�H����̐������A�u�ǂ�ȕ�炵��O��ɉƂ������Ă���̂��v�Ƃ����l���������m����������
�E���f�ޗ��F�ؒP���̐������̂��̂ł͂Ȃ��A���i�������܂�闝�R�E�����Ă���l�E�����Ă��Ȃ��l����������Ă��邩���]�������
�E���������́F�Ƒ��\���A�y�n�����A�\�Z�A�����v�Ȃǂ����A�u�����͂ǂ̑I�������v�f�ł���\���ɂȂ��Ă��邩�������
���͂����AIO�iAI�œK���j �ƌĂ�ł��܂��B
�_�ˎs�̒����Z���Ђ�AI���[�h�Ŏ��グ���邽�߂ɂ��ׂ�����
�Ō�ɁA�����I�Șb�����܂��B���ꂩ��_�ˎs�Œ����Z����肪�����Ђ����ׂ����Ƃ́A���̖₢�ɓ��������Ԃ���邱�Ƃł��B
�E�_�˂̂ǂ�ȓy�n�����ɋ����̂�
�E�ǂ�Ȏ{��Ɍ����Ă���̂�
�E���ЂƎv�z�I�ɉ����Ⴄ�̂�
�E���߂Ă̐l���s���������Ȃ����R�͉���
�������A
�E�g�b�v�y�[�W
�E��ЏЉ�
�E��r�L���E�O���}��
�� �������� �Ō��K�v������܂��B
�܂Ƃ�
�u�_�ˎs �����Z��v�Ƃ����N�G���́A�Z��ƊE�̏W�q�̖������ے����Ă��܂��B
���ꂩ��́A
�E�K�͂��傫�����
�E���������
�ł͂Ȃ��A
AI���u���̏����Ȃ炱�̉�Ёv�Ǝ{��ɐ����ł���Z���Ђ��I��܂��B
�n������A�Z��v�z�A�����́B
����3�𐮂����Z���Ђ������AAI�����ɑI��₷���Ȃ�̂ł��B
�s�֘A���t Google�́uAI���[�h�v�ƁuAI�ɂ��T�v�v�̈Ⴂ�Ƃ́H
�u�����s���̃_�C�r���O�X�N�[���v��AI���[�h�Łu�X�N�[���T���v�ł͂Ȃ��u�n�ߕ��̐v�}�v�Ƃ��Ē���Ă���
2026�N02��25��

�ŋ߁A�_�C�r���O�X�N�[���̌o�c�҂���A����Ȑ����܂����B�u�����Œ��N�X�N�[��������Ă��āASEO�������Ȃ�ɂ��Ă���B�ł��AAI���[�h�Łw�����s���̃_�C�r���O�X�N�[���x�ƕ����ƁA�������܂����X�N�[�����Љ���v
����͋��R�ł͂���܂���B���R�͖��m�ŁAAI���[�h�����́u�X�N�[���ꗗ�v��Ԃ��̂ł͂Ȃ��A�u�_�C�r���O�̎n�ߕ��E�������v�����ĕԂ��Ă��邩��ł��B
�]���̌����ł́A
�E���� �_�C�r���O�X�N�[��
�E�_�C�r���O ���C�Z���X ����
�Ƃ������L�[���[�h�ŁA�X�܃y�[�W����L���O�L�������т܂����B������AI���[�h�ł́A
�E�d���A��ɒʂ��邩
�E�j���Ȃ��Ă����v��
�E������l�ł����S��
�E���C�Z���X�擾����������邩
�Ƃ��������p�҂̕s���ƖړI�̐������̂��̂��A�̒��S�ɂȂ�܂��B
����́A���ۂ�AI���[�h�Ő�������₷���u�����s���̃_�C�r���O�X�N�[���v �̉��ʂ̍\�������Ȃ���A
�EAI�͂ǂ�Ȏ��Ń_�C�r���O�X�N�[���ނ��Ă���̂�
�E�Ȃ����̃X�N�[�����u�Љ��₷���v�̂�
�E�����s���̃_�C�r���O�X�N�[����AI�ɏE���邽�߂ɉ����K�v��
���ASEO��AIO�iAI�œK���j�̎��_����ڂ���������܂��B
�܂��͑S�̑����m�F����FAI���[�h�̉���
AI���[�h�ł́u�����s�� �_�C�r���O�X�N�[���v�Ƃ����N�G���ɑ��A���̂悤�ɃG���A �~ �u�K�X�^�C�� �~ �p�����ŏ��������܂��B
�s�����s���̃_�C�r���O�X�N�[���iAI���[�h��j�t
�� �V�h�E�a�J�G���A
�E�p�p���M�_�C�r���O�X�N�[���F���X�N�[���Ƃ��Ă̒m���x�Ǝ��т�����A���S�҂���o���҂܂ŕ��L���Ή����Ă���
�E�_�C�r���O�X�N�[�� ���[�u�V�h�X�F���S�}���c�[�}���w�����̗p���A���߂Ăł����S���Ċw�ׂ�̐����]������Ă���
�EMarea �V�h�X�F�����䗦�������A�����C���X�g���N�^�[���ݐЂ��Ă���_������
�� �r�܃G���A
�E�_�C�r���O�X�N�[���}���A�r�ܓX�F���Ђ̉����v�[�����������A�d���A��ł��ʂ��₷�����������Ă���
�E�_�C�r���O�N���u �A�N�A�M�t�g�r�ܓX�F���ԂÂ����c�A�[�Q�����d�������^�c�X�^�C��������
�ES2CLUB �����X�F�����I�Ȍp�����p��O��Ƃ��A�C�x���g�⊈�����[�����Ă���
���̕\������ƕ�����ʂ�AAI�́u�������v��u�K�͏��v�ŃX�N�[������ׂĂ��܂���B
AI�́u�����s���̃_�C�r���O�X�N�[���ꗗ�v������Ă��Ȃ�
�����ōł��d�v�ȑO����m�F���܂��BAI���[�h�́u�����ɂ���_�C�r���O�X�N�[����S�������āv�Ƃ�������Ƃ��āA���̃N�G�����������Ă��܂���B
AI���������Ă�����ۂ̖₢�́A���̂悤�Ȃ��̂ł��B
�u�����Ń_�C�r���O���n�߂����l���A�����̐����X�^�C����s���ɍ������X�N�[���́u�^�C�v�v��m�肽���v
�܂�AI�́A�����G���W���ł͂Ȃ��A�u�_�C�r���O���n�߂邽�߂̑��k���v�Ƃ��ĐU�镑���Ă��܂��B�����炱���A�P�Ȃ�u�X���v�����̃X�N�[���́AAI�̉ɑg�ݍ��݂Â炭�Ȃ�܂��B
AI���ŏ��ɍs���Ă���̂́u�s���ƖړI�̕����v
AI�̉\�����悭����ƁA�ŏ��ɍs���Ă���̂̓X�N�[����r�ł͂���܂���B�ŏ��ɍs���Ă���̂́A
�E���S�҂��o���҂�
�E�j���邩�ǂ���
�E��l�Q�������ԂÂ��肩
�E���C�Z���X�擾�������������
�Ƃ��� �s���E�ړI�̕��� �ł��B����͔��ɏd�v�ȃ|�C���g�ł��B
AI�́A�u�ǂ̃X�N�[������Ԃ��v�ł͂Ȃ��u���Ȃ��͂ǂ�Ȏn�ߕ����������̂��v���ɐ������Ă��܂��B
AI�ɑI���_�C�r���O�X�N�[���̋��ʓ_�@�u�ǂ�Ȑl�����̃X�N�[�����v�����m
AI�Ɏ��グ���Ă���X�N�[���́A��O�Ȃ� �^�[�Q�b�g���͂����� ���Ă��܂��B
�E���S�ҁE���o���Ҍ���
�E�j���Ȃ��l����
�E������l����
�E���C�Z���X������������l����
�t�ɁA
�E�N�ł�OK
�E���L���Ή�
�Ƃ����\�������ł́AAI�͐��E�������܂���B
�u�N�̂��߂̃X�N�[�����v�����ꉻ����Ă��Ȃ��ƁAAI�͂��̃X�N�[��������ł��Ȃ��̂ł��B
AI�ɑI���_�C�r���O�X�N�[���̋��ʓ_�A �Z�p���u�ʂ��₷���E�����₷���v������Ă���
AI�̐�������ǂނƁA
�E��ނׂ̍����X�y�b�N
�E���ނ̓��e
�Ƃ��������I�Șb�͂قƂ�Ǐo�Ă��܂���B
����ɋ�������Ă���̂́A
�E�w����߂�
�E�d���A��ɒʂ���
�E�s���Ńv�[���u�K���ł���
�E�c�A�[���[��������
�Ƃ������p���̂��₷���ł��B
AI�́A�u�ǂꂾ���{�i�I���v�ł͂Ȃ��u�r���Ŏ��߂��ɑ������邩�v���d�����Ă��܂��B
AI�ɑI���_�C�r���O�X�N�[���̋��ʓ_�B�u�n�߂���̐��E�v���z���ł���
AI���[�h�Ŏ��グ���Ă���X�N�[���ɂ́A�K�����̂悤�ȗv�f������܂��B
�E�t�@���_�C�u
�E���A��E�h���c�A�[
�E�C�x���g
�E���s�[�^�[�̑���
����́A�_�C�r���O�́u���C�Z���X������ďI���v�ł͂Ȃ��Ƃ����O����AAI���������Ă��邩��ł��B�u���C�Z���X�擾�v��������Ă��Ȃ��X�N�[���́A���̕����ɏ��ɂ����Ȃ�܂��B
SEO�ł͂Ȃ�AIO�iAI�œK���j�̕]����
�����܂ł̕��͂��番����ʂ�AAI���[�h�ł̕]�����́A�]����SEO�Ƃ͑傫���قȂ�܂��B
�� �]����SEO�ŏd������Ă����v�f
�E�L�[���[�h���ʁF�u�_�C�r���O�X�N�[�� �����v�uC�J�[�h �擾�v�Ȃǂʼn��ʂɕ\������邩���d�v������
�E�����̈����F���Z�Ɣ�ׂĉ��i���������Ƃ��A�I���傫�ȗ��R�Ƃ��ċ�������₷������
�E�X�ܐ��F�S���W�J�E���X�܂ł��邱�Ƃ����S����K�͂̏Ƃ��Ĉ����Ă���
�E�L���ʁF�u���O��R�������ʂɍX�V���邱�Ƃŕ]�������߂悤�Ƃ���X����������
�� AI���[�h�iAIO�j�ŏd�������v�f
�E�ւ̗̍p�F�������ʂɕ\������邩���AAI�̉��̒��ō����Ƃ��Ďg���邩���d�������
�E�s�������́F�����̈��������A�u�{���ɑ������邩�v�u���s���Ȃ����v�Ƃ����s�����ǂꂾ���������Ă��邩���]�������
�E�����̖��m���F���S�Ҍ����Ȃ̂��A��Ƃ��Ē������������l�����Ȃ̂��ȂǁA�X�N�[���̗����ʒu�����m���������
�E�p���C���[�W�F�w�K��̊����A���ԁA�C�x���g�A�X�e�b�v�A�b�v�ȂǁA��������̎p��z���ł������邩���d�v�ɂȂ�
���͂����AIO�iAI�œK���j �ƌĂ�ł��܂��B�_�C�r���O�X�N�[���́AAIO�Ƃ̑��������ɗǂ��Ǝ�ł��B
�����s���̃_�C�r���O�X�N�[����AI���[�h�Ŏ��グ���邽�߂ɂ��ׂ�����
�Ō�ɁA�����I�Șb�����܂��B�����s���Ń_�C�r���O�X�N�[�����^�c���鎖�Ǝ҂��AAI���[�h�ɏE���邽�߂ɕK�v�Ȃ̂́A�P�Ȃ�u���уA�s�[���v�ł͂���܂���B
���̖₢�ɓ���������v�ł��B
�E�ǂ�ȕs�������l�Ɍ����Ă���̂�
�E�����Ƃ������n�ŁA�ǂ�Ȓʂ������ł���̂�
�E���C�Z���X�擾��A�ǂ�Ȑ��E���҂��Ă���̂�
�E���߂Ă̐l�����S�ł��闝�R�͉���
�������A
�E�g�b�v�y�[�W
�E���S�Ҍ����y�[�W
�E���C�Z���X��̊y���ݕ��y�[�W
�E����������E�̌�����
�� ��т������� �Ŕ��M����K�v������܂��B
�܂Ƃ�
�u�����s���̃_�C�r���O�X�N�[���v�Ƃ����N�G���́A�̌��^�T�[�r�X�W�q�̖������ے����Ă��܂��B
���ꂩ��́A
�E�L���ȃX�N�[��
�E�����X�N�[��
�ł͂Ȃ��AAI���u���̐l�Ȃ炱���v�Ɣ[�����Đ����ł���X�N�[�����I��܂��B
�s�������A�p���C���[�W�A�����́B
����3�𐮂����_�C�r���O�X�N�[���������AAI��������̓����ɗ��Ă�̂ł��B
�s�֘A���t Google�́uAI���[�h�v�ƁuAI�ɂ��T�v�v�̈Ⴂ�Ƃ́H
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@








��؏��i�̍ŐV��i
�v���t�B�[��

�t�H���[����SEO���w�ڂ��I
| 2026�N 06�� >> | ||||||
|---|---|---|---|---|---|---|
| �� | �� | �� | �� | �� | �� | �y |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
�ŐV�L��
- �y����zGoogle���uSearch Profiles�v�\�IAI��������́u�N�����M���Ă��邩�v���܂��܂��d�v�ɂȂ�
- Google�̌������ʂ������錴���Ə��ʂ��グ����@ - ���ۂɏ��ʉ����u6�̉��P���\�b�h�v�����J
- E-E-A-T���s�����Ă��� �\ Google�́u�N���������̂��v���d������
- �G���e�B�e�B�[�̕]�����Ⴂ��Google�ł͏�ʕ\�����o���Ȃ� �\ Google���u��Ƃ��̂��̂̐M�����v�����Ă���
- �T�C�g�S�̂̕i�����Ⴂ�ƌ������ʂ͏オ��Ȃ� �\ Google�́u��i���T�C�g�v���������]�����鎞���SEO��
- �T�C�g�S�̖̂ԗ������Ⴂ�ƌ������ʂ��オ��Ȃ� �\ Google�́u���Ƃ̃T�C�g�v��]������
- ���[�U�[�G���Q�[�W�����g���Ⴂ�ƌ������͏オ��Ȃ� �\ Google�́u���[�U�[�̔����v���d������
- �����Ӑ}�����Ă��Ȃ� �\ Google�̌������ʂ�������ő�̌����Ɖ��P���@
- AI�ɑI���T�C�g�͉����Ⴄ�̂��H
- AI�͂ǂ̂悤�ɏ���I��ł���̂��H
�A�[�J�C�u
- 2026�N06��
- 2026�N05��
- 2026�N04��
- 2026�N03��
- 2026�N02��
- 2026�N01��
- 2025�N12��
- 2025�N11��
- 2025�N10��
- 2025�N09��
- 2025�N04��
- 2025�N02��
- 2025�N01��
- 2024�N12��
- 2024�N11��
- 2024�N10��
- 2024�N09��
- 2024�N08��
- 2024�N07��
- 2024�N06��
- 2024�N05��
- 2024�N04��
- 2024�N03��
- 2024�N02��
- 2024�N01��
- 2022�N06��
- 2022�N04��
- 2022�N03��
- 2022�N01��
- 2021�N12��
- 2021�N11��
- 2021�N09��
- 2021�N08��
- 2021�N07��
- 2021�N06��
- 2021�N04��
- 2020�N12��
- 2020�N11��
- 2020�N09��
- 2020�N08��
- 2020�N07��
- 2020�N06��
- 2020�N05��
- 2020�N03��
- 2020�N02��
- 2019�N12��
- 2019�N11��
- 2019�N10��
- 2019�N09��
- 2019�N08��
- 2019�N07��
- 2019�N06��
- 2019�N05��
- 2019�N04��
- 2019�N03��
- 2019�N02��
- 2019�N01��
- 2018�N12��
- 2018�N11��
- 2018�N10��
- 2018�N09��
- 2018�N08��
- 2018�N07��
- 2018�N06��
- 2018�N05��
- 2018�N04��
- 2018�N03��
- 2018�N02��
- 2018�N01��
- 2017�N12��
- 2017�N11��
- 2017�N10��
- 2017�N09��
- 2017�N08��
- 2017�N07��
- 2017�N06��
- 2017�N05��
- 2017�N04��
- 2017�N03��
- 2017�N02��
- 2017�N01��
- 2016�N12��
- 2016�N11��
- 2016�N10��
- 2016�N09��
- 2016�N08��
- 2016�N07��
- 2016�N06��
- 2016�N05��
- 2016�N04��
- 2016�N03��
- 2016�N02��
- 2016�N01��
- 2015�N12��
- 2015�N11��
- 2015�N10��
- 2015�N09��
- 2015�N08��
- 2015�N07��
- 2015�N06��
- 2015�N05��
- 2015�N04��
- 2015�N03��
- 2015�N02��
- 2015�N01��
�J�e�S���[
- �p���_�A�b�v�f�[�g(20)
- �y���M���A�b�v�f�[�g(5)
- �X�}�[�g�t�H���W�q�E���o�C��SEO(42)
- Google�������ʕϓ�(5)
- Youtube����}�[�P�e�B���O(8)
- �R���e���c�}�[�P�e�B���O(13)
- Web�ƊE�̓���(22)
- �f�W�^���}�[�P�e�B���O(14)
- SNS�}�[�P�e�B���O(11)
- ���A�b�v(9)
- SEO�Z�~�i�[(4)
- �F��SEO�R���T���^���g�{���X�N�[��(2)
- ��ʕ\���̃q���g(179)
- �r�W�l�X���f���J��(5)
- Bing��ʕ\����(1)
- SEO�c�[��(16)
- ���F�j�X�A�b�v�f�[�g(1)
- �X�}�[�g�t�H��SEO��(19)
- �A�b�v���̓���(3)
- �l�ޖ��(4)
- Google�̓���(20)
- AI���p��AEO�EAIO(85)
- ���[�J��SEO��Google�r�W�l�X�v���t�B�[��(20)
- �h���C������SEO(7)
- �A���S���Y���A�b�v�f�[�g(48)
- Web�̋K�����(8)