





SEO用語解説 - K
クローラーとは?SEO担当者として知っておきたいこと

執筆:一般社団法人全日本SEO協会代表理事 鈴木将司
作成:2021年8月14日
SEOの成功を目指すなら、Googleのアルゴリズムの構造を研究しないといけません。
たとえばGoogleは世界の検索市場を制覇した検索エンジンで、ほとんどの国々に普及しているのですが一方的に使われているだけではありません。その世界各国のWebサイトの情報を、なんと毎日欠かさず収集しているのです。
といってもGoogleは、情報を収集するために人を雇うようなことはしていません。世界各国の利用者から、情報をうまい具合に獲得できる仕組みを確立しているのです。
そのために使われているのが「クローラー」というシステムです。それはどのように作動しているのでしょうか?
クローラーとは? どのように開発された技術なのか?

クローラーが果たす役割は非常に大きい、非常に多いです。
Googleは、全世界のネットユーザが欲しがる情報を瞬時に届けるというサービスで有名です。ネット回線がまともである限り、検索結果を表示させる際に何十分も何時間もかかってしまうことはありません。
実際にGoogleの初期は、今と比べれば時間がかかっていたのですが。それでも、せいぜい数秒程度でした(今ならミリセカンド単位で結果が表示されます)。
しかしここで考えてみてください。Googleがいちいち、世界中のホームページを調べてから検索結果を表示しているのでしょうか?
もちろんそのようなことはありません。Googleはあらかじめ、情報を収集してストックしているのです。このように常日頃から準備ができているからこそ、Googleは超高速で検索結果をユーザに返すことができるのです。
そんな情報ストックの武器となっているソフトウェアが、「クローラー」です。
1.クローラー

クローラーの機能をよく知るには、有名ブランドのWebサイトを除いてみることがおすすめです。では、外車ファンの間では昔から有名な「ポルシェ」のWebサイトにアクセスしてみましょう。
現在はこのようなデザインですが、ポルシェのサイトは最初からこうだったのではありません。
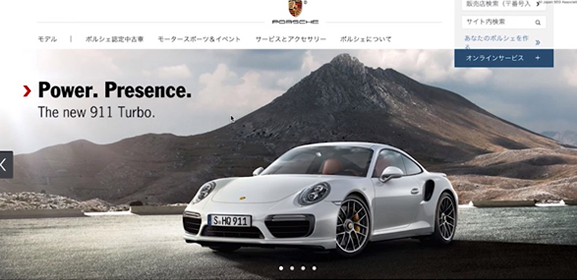
昔は、大きなインパクト満載の画像が使われていました。それから、画面いっぱいにFlashによる映像が出てきたことも、まだ記憶に新しいところです。
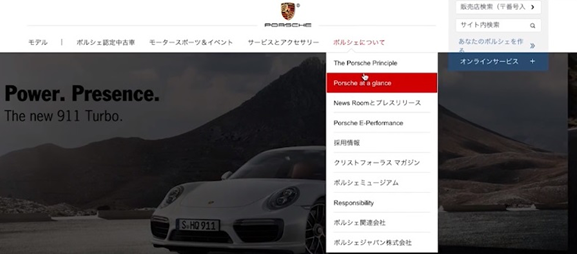
ちなみにFlashがトップページに使われていた時期は、すぐにサイト内に入りたいときはEnterを押下する必要がありました。すなわち急いでいるユーザにとっては不便な構造だったわけですが、それだけがデメリットだったのではありません。Googleのクローラーも入りにくかったのです。
しかし今はクローラーがサイト内に入り込んで、最短時間でインデックス(=情報をデータベースに登録すること)できるようになっています。
さてクローラーは、ポルシェのこの公式サイトにアクセスして、まずトップページの情報を全部取得して、Google側に送ります。Google内部には巨大なデータベースがあるため、すべてのデータを格納できるのです。
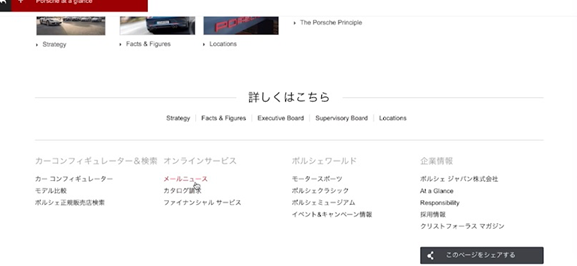
それからクローラーは、トップページにたくさん張られているリンクをたどります。そのようにして、サイト内の全ページの情報を取得してGoogleに送り返すのです
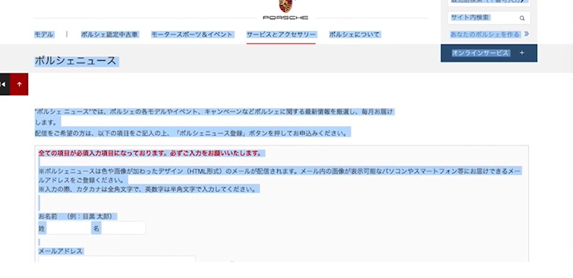
※それにしてもポルシェのWebサイト制作陣には、有能な人材がいるとしか思えません。なにしろGoogleのクローラーが、インデックスしやすいようなトップページを現在つくっていますから。
- たくさんのテキストリンクを張っている
- たくさんの画像リンクを張っている
これらは、クローラーのインデックス作業を助ける要素なのです。
Googleという企業が開発・導入したシステムは数多いですが、クローラーロボットというソフトウェアもそのひとつです。
このソフトウェアは常時インターネットで作動しています(全世界のネットの世界を自由に行き来できるのです)。そして全サイトのリンクをたどって、情報をことごとく収集・保存できる機能を与えられています。
※たとえば、世界中誰もが使っているサイトといえば、Yahoo!やWikipediaが有名でしょう。これらのサイトにリンクされているサイトは途方もない数ですが、クローラーロボットは膨大なリンクを精密に調査できるのです。
しかも、1日に何回もアクセスしていると考えられます。
実はクローラーロボットは、かつて「スパイダー(蜘蛛)」と呼ばれていました。
これは、インターネットが「World Wide Web(ワールドワイドウェブ)」というシステムで提供されていることが由来でしょう……World Wide Webの略名は「WWW」であり、そのままURLにも使われています。
インターネットの世界、World Wide Webにおいてはリンクがまさに蜘蛛の巣状態となっています。蜘蛛の巣のようにリンクという糸が張られている、と書いたほうがよいくらいです。
このエンドレスに続く蜘蛛の巣の上を、クローラーロボットが毎日何度も巡回しているのです。
2.インデックス

先ほど出てきたばかりですが「インデックスする」とは、どのような意味でしょうか?
インデックスとは、元来は「索引」「見出し」「指標」といったニュアンスの英単語です。その「索引」の意味が転じて、「データベースの検索速度を向上させるために作成される索引」といった意味合いで用いられる言葉になりました。
現在のWebサービスにおいては、「インデックスする」≒「サイトの情報を登録する」といった意図で使われる動詞と化している~、と書いてもよいでしょう。
では、クローラーとインデックスの関係を図式化しましたのでご覧ください。
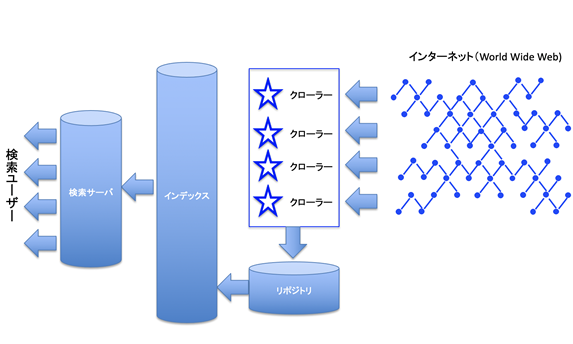
クローラーはWebサイトの情報をインデックスしますが、インデックスとは前述のように「索引」ですね。Googleは、世界中の全サイトの索引や目録・メニューを作成することを目標のひとつにしている、といえますね。

さて、クローラーはネット上の各ページの情報を、データベース内にインデックスして終わり…ではありません。「索引」「目録」というからには、整理されていないとおかしいです。 そこで、順序や序列をつけながら保存・管理するのです。
そして、インデックスされた情報はすべて、ネットユーザが検索をかけたときに素早く利用できる状態にならないといけません。言い換えますと、「キーワードに合わせて、順位付けできるシステム」が必要です……もしそれがないなら、ユーザに受け入れられる検索結果を出せないでしょう。
そこでGoogleは、ユーザが喜びそうな順序で、保存してあるデータを取り出して並べるために、独特の「アルゴリズム」を開発しました。
※もっとも「アルゴリズム」という言葉はGoogleの専売特許ではありません。プログラミングの世界でよく出てくる概念ですね。
SEOの世界では「Webページの評価をするための、たくさんの基準」といった意味合いで使われるようになっていますが。
Googleは200以上のアルゴリズムを持っていると推測されています。あいにくと、正確な分量は不明です。Googleはアルゴリズムの詳細を公開していませんから。
もし公開してしまったら、SEOはとても簡単になってしまいます。そうなると、アルゴリズムの秘密を知っている人が管理するサイトばかりが上位に来てしまうためユーザのためになりません……Googleはアルゴリズムの秘密が漏れないように厳重に管理していると思われます。
弊協会も継続して調査を続けていますが、アルゴリズムは大きく分けて7通りに分類できると推定しています。
現在のGoogleのアルゴリズムを構成する、7種類の重要な要素とは?

全日本SEO協会が設けた、アルゴリズムの7通りの分け方についてご説明しましょう。
1.コンテンツの独自性

クローラーがインデックスしたページに書かれている文章が、他のサイトのページ内にもあるのでしたら、評価は高まらないでしょう。
Googleはそのページにしか書いてないテキストを評価します。その評価したページを、検索順位を上げる材料にするのです。
よそのサイトの真似ばかりしていてはいけない、ということです。自分自身にしか書けない情報や知識があるならコンテンツに使いましょう。
2.外部サイトからのリンクの量・質

Googleが誕生してからしばらくの間は、外部サイトとSEOの関係は至極単純明快でした。リンクを受ける数が多ければ多いほど、検索順位が高くなったのです……まるで、選挙の投票システムのようでした。
それともう1点、ページランクが高いサイトからリンクを受けたほうが(ページランクが低いサイトからリンクされるよりも)検索順位が上がりやすいという性質も目立ちました。
これは今でも、有効なことは有効です。ただし、今では数だけで決まることはありません。質の高いリンクを集めることが必須です。外部ドメインのサイトからリンクを受けることはおろそかにできません。
3.ドメインの評価

これは、Webサイト内の各ページの評価ではありません。サイト全体の評価のようなものだととらえるとわかりやすいのではないでしょうか。
- サイトA:ページが多く、テーマも豊富なものの、人気のあるページは少数
- サイトB:ページ数が少ないものの、たくさんのユーザが読みに来るページが何ページもある
この2サイトを比較すれば、サイトBのほうが間違いなく高評価を受けるでしょう…これが、「人気ドメインになる」ということです。
ひとつひとつのページ自体に人気がなくても、人気ドメインになれれば、それだけで検索順位は上がりやすくなるのです。
人気がある個人や、人気がある団体や企業の公式サイトが自然と高い検索順位を保てるのは、この点が一因です。
4.ページ内におけるキーワードの分量

キーワードの分量はたびたび噂になってきましたが、アルゴリズムの作動結果を支える要素であることに疑いの余地はありません。
- サイトA:キーワードが2回しか書かれていない
- サイトB:キーワードが5回以上書かれている
この2サイトを比較すれば、Bのほうがユーザ(そのキーワードで検索をかけたユーザ)の欲する情報が入っている可能性が高いでしょう。
Googleのアルゴリズムはキーワードの分量を正確に集計していますが、そこには合理的な理由があるわけです。
5.サイト内におけるキーワードの分量
サイト全体でもキーワードは集計されていますね。
- サイトA:キーワードが書かれているページは2ページだけ
- サイトB:キーワードが書かれているページは全体の8割
Googleのアルゴリズムが評価するのがサイトBであることは明白です。サイト全体でキーワードが多いということは、そのキーワードに関する情報量が多くなるはずだからです。
6.URL

そのWebページのアドレスが、URLと呼ばれていますね(www.…)。
それではキーワードが「印鑑」である場合を想像してみましょう。(www.…)の中に、「印鑑」「inkan」といったワードが混ざっているなら、おそらくはそのサイトに含まれるメインの情報は印鑑である可能性が高いでしょう。
- サイトA:ドメインが「www.inkanhanbai.com」または「www.印鑑販売.com」
- サイトB:ドメインが「www.suzuki.com」または「www.鈴木.com」
どちらが印鑑をテーマにするサイトと考えられるでしょうか? サイトAでしょう。
※ドメインだけでなくページ単位で見る場合でも同じです。
「inkan.html」と「001.html」というページの場合なら前者が有利になります。
7.トラフィック

「トラフィック」とは、Webシステムの世界では「交通量」といったニュアンスを持つ言葉です。いわゆるサイトのアクセス数のことです。
早い話、ネットユーザの人数がトラフィックです。
- サイトA:人気があって訪問者がたくさんいるサイト
- サイトB:訪問者が少人数のサイト
このトラフィックという観点でも、Googleのアルゴリズムで評価するなら軍配が上がるのはサイトAです。
まとめ:クローラーの役割を知ると、SEOの目標も見えてくる
クローラーの役割や、インデックスやアルゴリズムとの関係を理解したら、SEOのためにどんなことをしたほうが得なのか想像ができるでしょう。
- クローラーロボットは日夜、世界中のWebサイトの情報を収集・保存している
- 自社サイトのトップページにFlashや巨大な画像ばかりを載せてテキスト(文字)やリンクが少ないと、クローラーがページ内から必要とする情報をスピーディーに収集することが困難になる
- トップページにはテキストリンクや画像リンクを増やしたほうがよい
- Googleはクローラーロボットが取得した情報を、独自の巨大なデータベース内に登録している(これが「インデックス」の過程)
- データベース内の情報に順序を設けて、検索結果の順位付けの材料とするのがアルゴリズム
- アルゴリズムの種類は200以上あるが、大きく分けると7通りになる
- コンテンツの独自性・質のよい外部サイトからの被リンク・ドメインの評価・ページ内およびサイト全体におけるキーワードの分量・訪問者数・ドメインへのキーワードの挿入……といった着眼点で、自社サイトの見直しを行うことでアルゴリズム対策に成功できる
クローラーロボットにうまいこと自社サイトの情報をインデックスしてもらうことや、アルゴリズムに高評価されるようなサイト改修を試みることが大事なのです。












